在科技飞速发展的今天,声纹识别技术正逐渐成为人们生活中的新兴宠儿,为各个领域带来了便捷与安全,声纹识别作为生物识别领域的一颗璀璨明珠,凭借其独特的优势和广泛的应用前景,吸引着越来越多的目光。
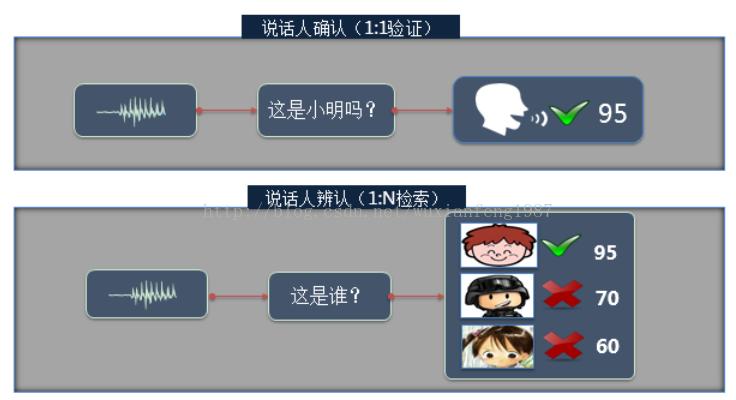
什么是声纹识别?
声纹识别,也被称为说话人识别,是一种通过分析语音信号中的特定特征来识别说话人身份的技术,它基于每个人声音的独特性,就像指纹一样独一无二,这种独特性主要由两个因素决定:一是发声腔的构造,包括咽喉、鼻腔和口腔等器官的形状、尺寸和位置,这些决定了声带张力的大小和声音频率的范围;二是发声器官被操纵的方式,如唇、齿、舌、软腭及腭肌肉等相互作用产生清晰语音的方式,每个人在学习说话的过程中,会逐渐形成自己独特的声纹特征。
声纹识别的核心概念与联系
语音特征
语音中包含的特征是声纹识别的关键要素,这些特征可以是时域特征,如均方误差(MSE)、自相关函数(ACF);也可以是频域特征,如快速傅里叶变换(FFT)、谱密度;还可以是时频域特征,如波形分析(WA),还有基于深度学习的特征提取方法,能够更有效地捕捉语音中的复杂结构和模式。
语音处理
语音处理是对语音数据进行预处理、滤波、分析等操作,以提取有用的信息,这有助于去除噪声、提高语音质量,并突出语音中的关键特征,为后续的声纹识别提供更好的基础。
语音识别与声纹识别
语音识别侧重于识别语音内容,而声纹识别则关注说话人的身份,语音识别将语音转换为文本数据,声纹识别根据语音特征识别人的身份,两者相辅相成,在某些应用场景中可以相互结合,为用户提供更全面的服务。
数学模型公式
在声纹识别中,常用的数学模型公式包括均方误差(MSE)用于衡量预测值与真实值之间的差异;自相关函数(ACF)用于描述信号序列在不同时间偏移下的相关性;快速傅里叶变换(FFT)将时域信号转换为频域信号;隐马尔可夫模型(HMM)用于描述时间序列数据的变化;深度神经网络(DNN)则用于处理大规模数据的复杂模式。
核心算法原理及具体操作步骤
语音特征提取
从语音数据中提取出与说话人身份相关的特征,常见的有:
- 时域特征:如均方误差(MSE)、自相关函数(ACF)等,通过分析语音信号在时域上的统计特性来提取特征。
- 频域特征:如快速傅里叶变换(FFT)、谱密度等,将语音信号转换到频域,观察其频率分布特点。
- 时频域特征:如波形分析(WA),综合考虑时间和频率维度上的信息。
- 基于深度学习的特征提取:利用深度神经网络自动学习语音中的复杂结构和模式,提取更具代表性的特征。
语音模型建立
根据语音特征数据训练出语音模型,常见的模型包括:
- 高斯混合模型(GMM):一种概率模型,用于估计概率密度函数,可以逼近任何形式的连续概率分布。
- 深度神经网络(DNN):具有强大的学习能力,可以处理大规模的语音数据,提取和匹配人的语音特征。
语音识别匹配
将待识别的语音数据与已建立的语音模型进行匹配,常见的方法有:
- 相似度计算:根据语音特征数据计算出两个语音序列之间的相似度,如欧氏距离、余弦相似度等。
- 决策规则:根据语音识别匹配结果进行身份识别,常见的决策规则包括阈值规则、多类别规则等。
未来发展趋势与挑战
发展趋势
- 技术创新:随着深度学习、人工智能等技术的不断发展,声纹识别系统将更加智能化和高效化,结合图像识别、语音助手等技术,为用户提供更便捷的服务。
- 应用扩展:声纹识别将在更多领域得到应用,如金融、医疗、教育、娱乐等,为人们的生活带来更多便利。
挑战
- 数据不足:声纹识别系统需要大量的语音数据进行训练和测试,但实际数据集往往不足以满足需求,需要寻求更高效的数据收集和处理方法。
- 声纹篡改:恶意用户可能进行声纹篡改,以绕过系统的识别,这需要在系统设计中加入更高级别的安全措施,防止声纹被非法复制或伪造。
- 跨语言和跨文化:不同语言和文化背景下的语音数据存在差异,这对声纹识别系统提出了更高的要求,需要在系统设计中加入多样化的语言和文化特征,提高系统的适应性和准确性。
声纹识别技术是一项极具潜力的生物识别技术,它以其独特的优势和广泛的应用前景,为人们的生活带来了更多的便利和安全保障,尽管目前仍面临一些挑战,但随着技术的不断进步和完善,相信声纹识别技术将在未来发挥更加重要的作用。