本文目录导读:
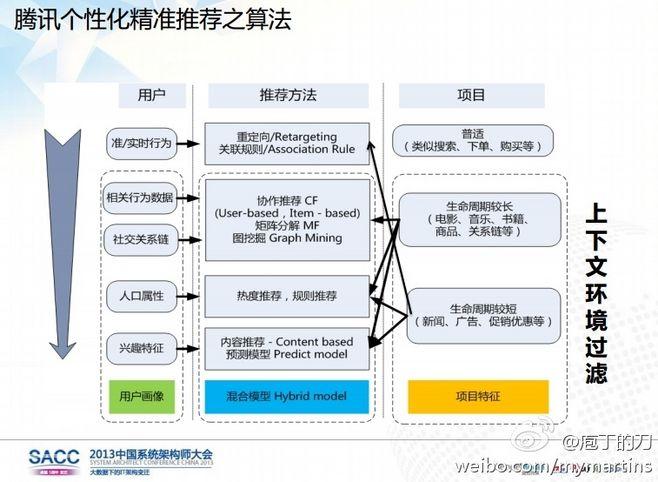
在当今信息爆炸的时代,我们每天都会接收到海量的信息,无论是在购物网站浏览商品、在视频平台观看视频,还是在使用音乐软件听歌,个性化推荐系统都如影随形,它能够根据我们的行为、偏好等,为我们精准推送符合兴趣的内容,让信息更有价值,让我们的体验更加便捷和愉悦,个性化推荐算法究竟是如何做到这一切的呢?
数据收集:个性化推荐的基石
个性化推荐的第一步是广泛收集用户数据,这些数据来源丰富多样,包括用户的基本信息,如年龄、性别、地理位置等;用户的历史行为数据,像购买记录、浏览历史、搜索关键词、收藏和点赞等;还有用户的社交数据,例如在社交平台上的朋友关系、关注列表、分享内容等,通过多渠道、全方位地收集这些数据,系统能够初步了解用户的大致特征和兴趣爱好。
电商平台会记录用户购买的商品类别、品牌、价格区间等信息,分析出用户对不同类型商品的喜爱程度,音乐平台则会统计用户经常收听的歌曲风格、歌手性别、语种偏好等,为后续的个性化推荐奠定基础,这些数据如同一块块拼图,虽然单独看起来可能意义有限,但当它们汇聚在一起时,就能勾勒出用户独特的“兴趣画像”。
常见算法:挖掘数据背后的规律
1、协同过滤算法
协同过滤算法是个性化推荐中应用最广泛的算法之一,它分为基于用户的协同过滤和基于物品的协同过滤。
- 基于用户的协同过滤:核心思想是“物以类聚,人以群分”,它假设如果两个用户在过去对很多物品的偏好相似,那么他们对其他物品的评价也很可能相似,用户 A 和用户 B 都购买了《百年孤独》《平凡的世界》等书籍,系统就认为他们有相似的兴趣,当发现用户 A 购买了一本新的科幻小说《三体》,就会将《三体》推荐给用户 B,这种算法的优点是能够发现用户潜在的新兴趣,但对于新用户或活跃度较低的用户,由于其行为数据较少,难以找到相似的用户群体,推荐效果可能会受到影响。
- 基于物品的协同过滤:则是依据“如果你喜欢某个物品 A,那么你可能也会喜欢与 A 相似的物品 B”的原理,它会计算物品之间的相似度,比如通过分析商品的标签、描述、被相同用户购买或浏览的次数等,一部电影《泰坦尼克号》和《阿甘正传》都被同一类用户群体所喜爱,因为它们在爱情、励志等主题上有相似之处,所以如果用户对其中一部电影感兴趣,另一部就可能被推荐给他,该算法对于新物品的推荐比较有效,因为它不依赖于用户对新物品的历史评价,但可能会过度推荐热门物品,导致推荐的多样性不足。
2、基于内容的推荐算法
基于内容的推荐主要聚焦于物品本身的特征,它通过对物品的属性进行提取和分析,如文本信息(文章的主题、关键词、作者)、图像信息(颜色、纹理、形状)、音频信息(节奏、旋律、歌词)等,然后根据用户过去对具有某些特征物品的偏好,来推荐具有相似特征的其他物品。
新闻推荐系统会提取新闻的标题、关键词等文本内容,如果用户经常阅读科技类新闻,系统就会优先推荐包含科技相关关键词的新闻文章,这种算法的优点是能够为用户提供与其兴趣紧密相关的物品,并且对于新物品和新用户都能有较好的适应性,不过,它的缺点在于难以捕捉用户的一些潜在兴趣,因为只考虑了物品本身的特征,而没有充分考虑用户的个性化需求和上下文信息。
3、深度学习算法
随着人工智能技术的飞速发展,深度学习算法在个性化推荐领域崭露头角,深度学习模型如神经网络、卷积神经网络(CNN)、循环神经网络(RNN)及其变体长短期记忆网络(LSTM)等,能够自动学习数据中的复杂模式和非线性关系。
在图像推荐中,CNN 可以提取图像的深层次特征,更好地理解图像的内容和风格;在序列数据推荐(如用户的历史浏览顺序)中,RNN 和 LSTM 能够处理数据的时序信息,预测用户下一步可能感兴趣的物品,深度学习算法的优势在于其强大的表达能力和对复杂数据的处理能力,但它需要大量的训练数据和较高的计算资源,训练过程也相对复杂和耗时。
模型优化:提升推荐的精准度
为了提高个性化推荐的准确性和有效性,还需要对推荐模型进行不断的优化。
1、数据预处理
在数据收集过程中,难免会存在噪声数据、缺失数据和异常数据等问题,数据预处理就是要对这些数据进行清洗、填充和转换等操作,去除重复的用户行为记录,填补缺失的年龄、性别等基本信息,将非数值型的数据(如性别)进行编码转换为数值型数据,以便模型能够更好地处理,还会对数据进行标准化处理,使不同特征的数据具有相同的尺度,避免某些特征因数值过大或过小而主导模型的训练过程。
2、特征工程
选择合适的特征对于模型的性能至关重要,特征工程包括特征选择、特征提取和特征构建,通过相关性分析、主成分分析等方法选择与用户兴趣高度相关的特征,去除无关或冗余的特征,降低数据的维度,在电影推荐中,如果发现用户对电影的评分与电影的票房收入相关性较低,而与电影的类型、导演等因素相关性较高,就可以重点选择这些相关特征进行建模,还可以通过组合多个特征创建新的特征,如将用户的浏览时间、浏览频率与浏览的页面类型相结合,形成一个新的特征来更全面地描述用户的浏览行为。
3、参数调整
不同的推荐算法都有各自的参数,如协同过滤算法中的邻居数量、相似度计算方法的参数,深度学习算法中的学习率、隐藏层层数、神经元数量等,通过交叉验证、网格搜索等方法对参数进行调整和优化,找到一组最优的参数组合,使模型在训练集和测试集上都能达到较好的性能表现,在基于神经网络的推荐模型中,逐渐调整学习率和隐藏层的神经元数量,观察模型在验证集上的准确率、召回率等指标的变化,直到找到最佳的参数设置。
冷启动问题:挑战与解决方法
在个性化推荐系统中,冷启动是一个不可忽视的问题,主要包括新用户冷启动和新物品冷启动。
1、新用户冷启动
对于新用户,由于缺乏足够的历史行为数据,很难准确地了解他们的兴趣偏好,一种解决方法是采用基于人口统计学信息的推荐策略,如根据新用户的注册信息(年龄、性别、地区等),为其推荐适合该群体的热门物品或通用性较强的内容,另一种方法是利用社交网络信息,如果新用户通过社交账号登录,可以参考其社交好友的兴趣偏好来为其进行初步的推荐,新用户登录音乐平台后,根据其微信好友经常收听的歌曲类型,为其推荐类似的音乐曲目。
2、新物品冷启动
新物品刚进入系统时,没有用户与之交互的数据,难以确定其适合的受众群体,常见的做法是基于物品的内容特征进行推荐,比如对于一本新出版的书籍,根据其题材、作者风格、出版社等信息,将其推荐给对类似题材书籍感兴趣的用户,还可以通过邀请领域专家或意见领袖对新物品进行评价和推荐,借助他们的影响力吸引早期用户的关注和尝试。
个性化推荐算法在当今互联网时代发挥着极为重要的作用,它帮助人们在信息海洋中找到自己真正感兴趣的内容,提高了信息获取的效率和质量,随着技术的不断发展和用户需求的日益多样化,个性化推荐算法也面临着诸多挑战,如数据隐私保护、算法可解释性、应对虚假数据等问题,未来,研究人员将继续探索创新,不断优化和完善个性化推荐算法,为用户提供更加精准、智能、个性化的服务体验,同时也要在满足用户个性化需求和保护用户隐私之间找到更好的平衡点,推动互联网行业的健康可持续发展。