在当今科技飞速发展的时代,强化学习作为人工智能领域的关键分支,正逐渐改变着我们的生活与世界,它犹如一位智慧的探索者,通过不断地试错与学习,在复杂的环境中寻找最优的策略,为众多领域带来了前所未有的创新与突破。
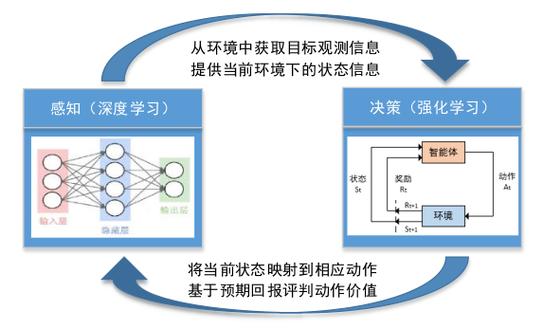
强化学习的理论基础扎根于行为心理学和马尔可夫决策过程,其核心概念围绕着智能体、环境、状态、动作与奖励展开,智能体如同具有学习能力的个体,在特定环境中感知状态信息,依据策略选择动作,进而获得来自环境的即时奖励反馈,这一奖励信号是引导智能体行为优化的关键因素,它促使智能体朝着能够长期累积最大奖励的方向调整策略,在一个机器人导航的任务中,机器人(智能体)所处的空间位置、周围障碍物分布等构成环境状态,它可以选择向不同方向移动等动作,若成功避开障碍且朝着目标前进,则会获得正向奖励,反之则可能得到负向惩罚。
从学习算法的角度,强化学习可分为基于值函数的方法与基于策略梯度的方法,基于值函数的方法旨在估计在每个状态下智能体所能获得的价值,如 Q-learning 算法通过不断更新状态 - 动作对的价值函数 Q(s,a),使智能体能够根据当前状态选择具有最高价值的动作,而策略梯度方法则直接对策略参数进行优化,通过计算奖励关于策略参数的梯度来更新策略,像 REINFORCE 算法便是此类方法的典型代表,它能更高效地处理高维动作空间问题。
深度学习与强化学习的结合——深度强化学习,更是将强化学习推向了新的高度,深度神经网络强大的特征表达能力为处理复杂的环境感知信息提供了有力工具,在图像识别任务驱动的游戏中,深度卷积神经网络可以提取游戏画面中的丰富视觉特征,如物体形状、纹理等信息,然后结合强化学习算法,使智能体能够根据这些特征做出更精准的游戏操作决策,AlphaGo 便是深度强化学习在围棋领域取得巨大成功的典范,它通过海量的棋局数据训练深度神经网络来评估棋局形势,再运用强化学习策略优化下棋策略,最终战胜了人类顶尖棋手,这一成就震撼了全球。
在实际应用方面,强化学习展现出了广泛的潜力,在工业制造领域,强化学习可用于优化生产线的调度,智能体通过学习不同生产任务的排列组合对生产效率、成本等指标的影响,找到最优的生产调度方案,从而提高企业的经济效益与竞争力,在智能交通系统中,它能够帮助交通信号灯控制系统自适应地调整信号时长,根据实时交通流量情况减少车辆排队等待时间,缓解城市交通拥堵问题,在医疗领域,强化学习可用于优化药物研发流程,通过模拟药物分子与靶点的相互作用过程,加速新药的研发进度并降低成本。
强化学习也面临着诸多挑战,其中样本效率问题是关键瓶颈之一,许多强化学习算法需要大量的环境交互样本才能学习到有效的策略,这在一些真实世界的复杂场景中往往难以实现,在自动驾驶汽车的训练中,获取大量实际驾驶场景数据不仅成本高昂,且存在安全隐患,强化学习的稳定性也是一个重要考量因素,由于环境的随机性与不确定性,智能体在学习过程中可能会出现策略波动较大、难以收敛到最优解的情况。
为了克服这些挑战,研究人员提出了一系列改进方法,迁移学习技术被应用于强化学习中,通过利用在源任务中学习到的知识来加速目标任务的学习过程,提高样本效率,在多个类似的机器人控制任务之间进行知识迁移,使新任务中的智能体能够更快地适应环境并学习到有效策略,在稳定性方面,一些新的算法设计如双 Q 网络、深度确定性 策略梯度(DDPG)等通过改进价值函数估计与策略更新的方式,增强了学习过程的稳定性,减少了策略的大幅波动。
展望未来,随着计算能力的不断提升、算法的持续创新以及多学科融合的深化,强化学习有望在更多领域创造出令人瞩目的成就,它将在人机协作、智能家居、智能安防等新兴场景中扮演更为重要的角色,为构建更加智能化、高效化的社会提供坚实的技术支撑,我们有理由相信,强化学习这把开启智能未来之门的钥匙,将在科技发展的长河中绽放出更为璀璨的光芒,引领我们走向一个充满无限可能的新纪元。