在当今数字化时代,图像识别作为人工智能领域的关键组成部分,正以前所未有的速度改变着我们的生活、工作和社会的方方面面,它就像一双拥有神奇魔力的眼睛,能够精准地“看”懂图像中蕴含的各种信息,无论是识别人脸、检测物体,还是理解场景等,都展现出了巨大的应用潜力和价值。
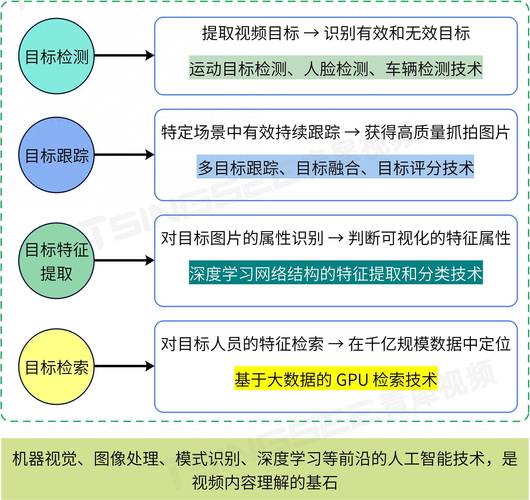
从技术原理层面来看,图像识别主要依赖于机器学习算法,尤其是深度学习中的卷积神经网络(CNN),CNN 的结构模仿了人类视觉系统的层次化处理方式,最初层会提取图像中的简单特征,比如边缘、纹理等基本元素;随着层级的深入,这些简单特征被逐步组合、抽象成更复杂的语义信息,在人脸识别应用中,通过大量带有标注的人脸图像数据来训练 CNN 模型,让它学习到不同人脸的独特特征模式,从而在后续遇到新的人脸图像时,能够准确地判断出其身份。
在实际应用方面,图像识别已经渗透到了众多行业,在医疗领域,它可以辅助医生进行医学影像分析,快速准确地检测出 X 光、CT 等影像中的病变区域,像早期肿瘤的筛查等,大大提高了诊断的准确性和效率,为患者的治疗争取了宝贵时间,在交通行业,智能监控系统利用图像识别技术对道路上的车辆、行人、交通标志等进行实时监测和识别,一方面可以实现交通流量的精准统计和路况的动态监测,另一方面也能有效保障交通安全,比如识别闯红灯、超速等违规行为并及时预警。
在零售行业,基于图像识别的自助收银系统逐渐兴起,顾客只需将购买的商品放置在识别区域,系统就能通过图像分析自动识别商品的种类、数量等信息,完成结账过程,极大地提升了购物的便捷性,减少了人工收银的排队等待时间,商家还可以借助图像识别对店内顾客的行为进行分析,了解顾客的行走路线、停留区域等,从而优化商品陈列和店铺布局。
图像识别技术的发展也并非一帆风顺,面临着诸多挑战,数据质量就是其中一个关键问题,高质量的标注数据对于训练准确的图像识别模型至关重要,如果数据标注不准确或者存在偏差,那么模型学习到的特征就可能存在错误,导致识别结果出现偏差,在一些图像分类任务中,如果训练数据集中某些类别的样本数量过少或者标注模糊不清,模型就很难准确地对这些类别进行识别。
计算资源也是制约图像识别广泛应用的一个因素,复杂的深度学习模型需要大量的计算能力来进行训练和推理,高性能的 GPU 集群等计算设备价格昂贵,对于一些中小企业或者研究机构来说,获取足够的计算资源存在一定难度,而且,模型的训练过程往往耗时较长,如何提高训练效率、降低计算成本是当前研究的重要方向之一。
为了应对这些挑战,研究人员正在不断探索新的解决方案,在数据方面,开发更高效的数据标注工具和方法,利用众包等方式扩大数据标注的规模和质量,在计算资源上,一方面研发更高效的模型结构和算法,减少对计算资源的依赖;推动硬件技术的不断创新,提高芯片的计算性能,降低成本。
展望未来,图像识别技术有着广阔的发展前景,随着技术的不断进步和应用的持续拓展,它将更加深入地融入到我们的日常生活和社会的各个角落,或许在不久的将来,我们身边的各种智能设备都能凭借精准的图像识别能力,为我们提供更加个性化、智能化的服务,让我们的生活变得更加便捷、高效和丰富多彩,开启一个全新的智能视觉时代,而这也将进一步推动人类社会向着更高水平的数字化、智能化迈进。