本文目录导读:
在当今科技飞速发展的时代,语音识别技术正以前所未有的速度改变着我们的生活、工作和社交方式,它就像一座无形的桥梁,将人类的语音指令与数字设备的智能响应紧密相连,让信息交互变得更加自然、便捷和高效。
语音识别的原理探秘
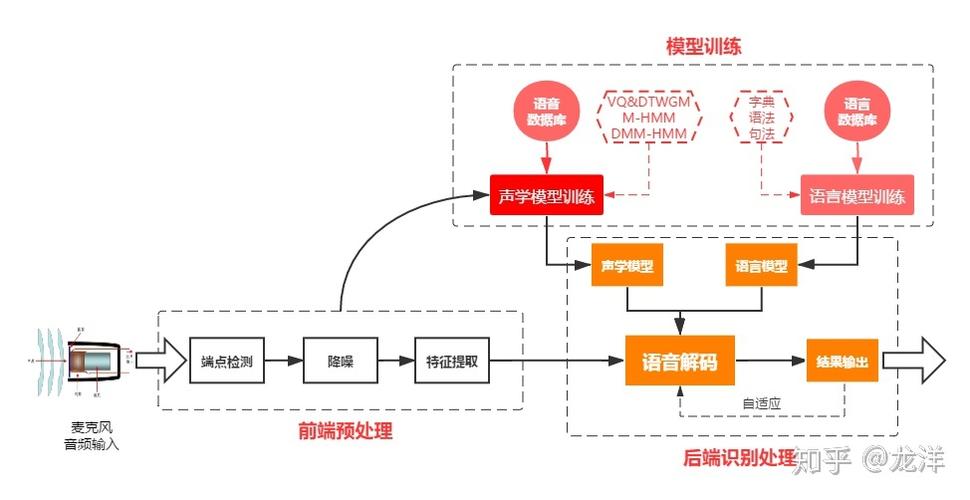
语音识别是一个复杂的多学科交叉领域,涉及到声学、语言学、信号处理、人工智能等多个领域的知识,其核心过程大致可分为以下几个关键步骤:
(一)语音信号采集
这是语音识别的基础环节,通过麦克风等音频采集设备,将人类发出的语音声波转换为电信号,这些电信号通常具有连续的波形,包含了语音的频率、幅度、时长等各种特征信息,是后续处理的原始数据来源,当我们对着手机说“播放音乐”时,手机麦克风捕捉到我们声音的振动并转化为相应的电信号。
(二)预处理
由于采集到的原始语音信号往往存在噪声干扰(如环境噪音、背景杂音等)、信号失真等问题,需要进行预处理来提高信号质量,常见的预处理操作包括滤波、降噪、预加重、采样、量化等,滤波可以去除高频或低频噪声,降噪算法则采用各种技术手段抑制背景噪音,预加重能够提升语音信号的高频成分能量,使其频谱更加平坦,而采样和量化则是将连续的模拟信号转换为离散的数字信号,以便计算机进行处理,在嘈杂的环境中使用语音助手时,预处理模块会努力过滤掉周围环境的嘈杂声,突出我们的语音指令。
(三)特征提取
经过预处理后的语音信号仍然包含大量数据,需要提取出能够代表语音本质特征的关键参数,目前常用的特征参数有梅尔频率倒谱系数(MFCC)、线性预测编码(LPC)等,MFCC 是基于人耳听觉感知特性提出的,它能够有效地捕捉语音的频谱特征,反映了语音在不同频率上的能量分布情况;LPC 则是基于语音信号的线性预测模型计算得到的一组系数,主要用于描述语音的声道特性,这些特征参数将作为语音的数字化表示,输入到后续的识别模型中,不同的人在说同一个字时,其语音的特征参数会有所不同,但通过提取这些关键特征,系统可以识别出相同的语音内容。
(四)声学模型训练
声学模型是语音识别系统中的重要组成部分,它用于建立语音特征参数与对应的语音单元(如音素、音节、单词等)之间的映射关系,通过对大量的语音数据进行学习和训练,声学模型可以准确地计算出给定语音特征序列属于各个语音单元的概率分布,常见的声学模型有高斯混合模型(GMM)、深度神经网络(DNN)以及近年来兴起的端到端模型如卷积神经网络(CNN)与循环神经网络(RNN)的结合等,GMM 通过多个高斯分布函数的组合来拟合语音特征的分布规律;DNN 则具有更强大的非线性表达能力,能够自动学习到更复杂的语音模式;而 CNN 与 RNN 的结合可以充分利用语音的时空特性,进一步提高识别准确性,使用大量不同人的语音样本来训练声学模型,使其能够适应各种发音特点和口音变化,从而更准确地识别语音。
(五)语言模型构建与解码
语言模型用于对语音识别的结果进行语义理解和后处理,它考虑了语言中的语法规则、语义信息和上下文关联等因素,语言模型可以根据已知的前 N - 1 个词预测第 N 个词出现的概率,从而帮助系统在多个可能的识别结果中选择最合理、最符合语言逻辑的输出,常见的语言模型有 N 元文法模型、隐马尔可夫模型(HMM)、基于深度学习的神经网络语言模型等,在解码阶段,系统结合声学模型和语言模型的概率得分,通过特定的搜索算法(如维特比算法)找到概率最高的词序列作为最终的识别结果,当识别一句话时,语言模型会根据前面的词语推测下一个可能出现的词语,提高识别的准确性和可读性。
语音识别的应用领域
随着语音识别技术的不断成熟和普及,其应用领域日益广泛,涵盖了生活的方方面面,为人们带来了极大的便利和创新体验。
(一)智能语音助手
智能语音助手如苹果的 Siri、亚马逊的 Alexa、百度的小度等已经成为人们日常生活中不可或缺的一部分,它们可以通过语音交互的方式为用户提供信息查询、日程安排、音乐播放、智能家居控制等多种服务,我们可以对 Siri 说“明天早上八点叫我起床”,它会自动设置闹钟;对小度说“我想听一首周杰伦的歌”,它就会为我们播放相关歌曲,智能语音助手不仅提高了人们的生活效率,还为那些不便于使用双手操作的场景(如驾驶、做家务等)提供了更加安全便捷的交互方式。
(二)语音输入法
语音输入法改变了传统的文字输入方式,使人们在移动设备、电脑等终端上输入文字更加快速、便捷,用户只需说出想要输入的内容,系统就能将其准确转化为文字形式,这对于一些打字速度较慢或者在特殊情况下不方便打字的用户来说尤为重要,如老年人、视力障碍者等,目前,各大手机厂商和互联网公司都推出了自己的语音输入法产品,并且不断优化其识别准确率和响应速度,讯飞输入法凭借其先进的语音识别技术,在市场中占据了较高的份额,受到了广大用户的喜爱。
(三)车载语音系统
车载语音系统为驾驶员提供了一个更加安全、舒适的驾驶环境,驾驶员可以通过语音指令控制车辆的各种功能,如导航、多媒体播放、空调调节、电话接听等,无需分散注意力去手动操作按钮,这不仅提高了驾驶的安全性,还增加了驾驶的乐趣,奔驰、宝马等豪华汽车品牌都配备了先进的车载语音控制系统,车主可以说“导航到最近的加油站”“播放我喜欢的音乐频道”等指令来控制车辆的相关功能。
(四)客户服务
在客服领域,语音识别技术被广泛应用于智能客服系统中,企业可以利用语音识别和自然语言处理技术实现自动化的客户服务流程,如客户咨询解答、投诉处理、业务办理等,智能客服系统能够快速理解客户的问题并提供准确的回答,大大提高了客户服务效率和质量,降低了企业的人力成本,银行的客服中心可以使用智能客服系统为客户办理账户查询、转账汇款等业务,客户只需通过电话说出自己的需求,系统就能自动完成相关操作并给出反馈。
(五)医疗健康
语音识别在医疗健康领域也有重要应用,医生可以通过语音记录患者的病历信息,提高病历书写的效率和准确性;患者也可以通过语音与医疗应用程序进行交互,查询疾病信息、预约挂号等,语音识别还可以用于远程医疗诊断,患者可以通过语音描述症状,医生根据语音分析结果进行初步诊断和建议,一些医院已经开始使用语音电子病历系统,方便医生在诊疗过程中快速记录患者病情,同时也便于后续的信息共享和研究。
语音识别面临的挑战与发展趋势
尽管语音识别技术取得了显著的进步,但在实际应用中仍然面临着一些挑战。
(一)复杂环境下的识别准确性
在噪声较大、多人说话、口音浓重等复杂环境中,语音识别的准确性会受到较大影响,在工厂车间、繁华街道等噪音环境中,语音识别系统可能会出现误识别或无法识别的情况;对于带有方言口音的语音,系统的识别难度也会增加,研究人员正在不断研发新的算法和技术,如自适应滤波、深度学习中的鲁棒性训练方法等,以提高语音识别系统在复杂环境下的性能。
(二)多语言支持与跨文化交流
随着全球化的发展,人们对多语言语音识别的需求日益增长,不同语言具有不同的语法结构、词汇体系和发音特点,开发支持多种语言的语音识别系统面临诸多技术难题,在跨文化交流中,还存在语言习惯、文化背景等方面的差异,这给语音识别的应用带来了一定挑战,未来,研究人员将致力于开发更加通用的多语言语音识别模型,同时结合文化因素进行优化,以实现更好的跨文化交流效果。
(三)隐私与安全问题
语音识别系统需要采集用户的语音数据进行分析处理,这就涉及到用户隐私保护问题,如果这些数据被不当获取或滥用,可能会对用户的个人隐私造成侵犯,如何确保语音数据的安全可靠存储和使用是语音识别技术发展过程中必须解决的重要问题,加密技术、访问控制机制、数据脱敏等手段将在未来得到更广泛的应用,以保障用户隐私安全。
展望未来,语音识别技术将朝着更加智能化、个性化、精准化的方向发展,随着人工智能技术的不断突破和创新,语音识别系统将更好地理解人类的语言和意图,与人们的交互将更加自然流畅,为人类社会带来更多的便利和惊喜,它将不仅仅是一个简单的工具,而是成为人们生活中无处不在、无所不能的智能伙伴,助力我们开启更加美好的未来生活篇章。