一、引言
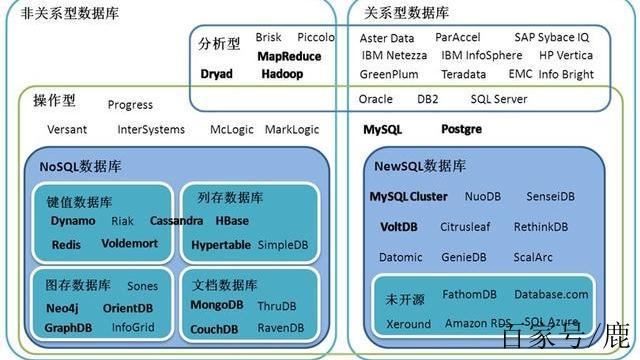
在当今数字化时代,数据量呈爆炸式增长,传统的关系型数据库在某些场景下面临着性能瓶颈和扩展性挑战,非关系型数据库作为一种新兴的数据存储技术,逐渐崭露头角并得到广泛应用,它以独特的存储结构和数据处理方式,为各类复杂数据的高效存储和管理提供了新的解决方案,在互联网、大数据、物联网等诸多领域发挥着重要作用。
二、非关系型数据库的原理
(一)键值对存储
1、基本原理
键值对存储是最简单的非关系型数据库模型之一,它将数据表示为键值对的形式,其中键是唯一的标识符,用于快速查找对应的值,这种存储方式类似于现实生活中的字典,通过键可以迅速定位到与之关联的值。
2、示例
在一个缓存系统中,可以使用键值对存储来缓存用户会话信息,键可以是用户的会话 ID,值则是包含用户登录状态、权限等相关信息的数据结构,当需要获取某个用户的会话信息时,只需根据会话 ID 作为键进行查询,即可快速返回对应的值,大大提高了数据访问速度。
(二)文档存储
1、基本原理
文档存储以文档为单位存储数据,每个文档可以包含复杂的嵌套结构,如对象、数组等,文档通常使用 JSON、XML 等格式进行表示,这种格式具有良好的可读性和扩展性,能够方便地存储和处理各种类型的数据。
2、示例
以一个内容管理系统为例,一篇文章可以作为一个文档存储在文档数据库中,文章的标题、作者、发布时间、正文内容等信息都可以包含在同一个文档内,而且,如果文章还包含评论功能,评论也可以作为嵌套的文档存储在文章中,这样便于对整篇文章及其相关评论进行整体管理和查询。
(三)列族存储
1、基本原理
列族存储将数据按照列族进行分组存储,每个列族包含了具有相同性质的一组列,与传统的关系型数据库按行存储不同,列族存储在读取特定列的数据时效率更高,尤其适用于处理大量稀疏数据的情况,因为只有需要的列会被读取和处理。
2、示例
在大数据分析场景中,假设有一个记录用户行为数据的表格,包含用户 ID、浏览页面、浏览时间、购买商品等众多列,如果大部分用户没有购买行为,那么购买商品这一列对于很多用户来说是空值,采用列族存储时,可以将用户 ID 列族单独存储,浏览页面列族单独存储等,当分析用户浏览行为时,只需读取浏览页面相关的列族,避免了读取大量无用的空值列,从而提高了查询性能。
(四)图形数据库
1、基本原理
图形数据库基于图论原理构建,用节点和边来表示实体及其之间的关系,节点代表实体对象,如人、地点、事件等,边则表示实体之间的联系,如人与人之间的朋友关系、地点与事件的所属关系等,通过遍历图中的节点和边,可以方便地进行复杂的关系查询和分析。
2、示例
在社交网络分析中,图形数据库非常适用,要查找某个人的二度人脉关系(即朋友的朋友),在图形数据库中,可以轻松地从该人对应的节点出发,沿着与朋友的边找到其直接朋友的节点,然后再进一步沿着这些朋友与其他人的边找到二度人脉关系的节点,这种基于图形结构的查询方式比在关系型数据库中使用复杂的 SQL 连接查询要高效得多。
三、非关系型数据库的特点
(一)灵活性高
1、数据模型灵活
非关系型数据库不局限于固定的表结构,可以根据不同的应用需求选择合适的数据模型,如键值对、文档、列族或图形等,这使得开发人员能够更自由地设计数据存储方案,适应各种复杂的数据结构和业务逻辑。
2、支持多种数据类型
能够轻松处理结构化、半结构化和非结构化数据,无论是文本、图像、音频、视频还是复杂的嵌套数据结构,都可以在非关系型数据库中找到合适的存储方式,无需像关系型数据库那样进行繁琐的转换和适配。
(二)可扩展性强
1、水平扩展能力
非关系型数据库通常具有良好的水平扩展能力,可以通过增加服务器节点来分担负载和存储数据,随着数据量的不断增长,只需简单地添加新的节点到集群中,就能实现系统的无缝扩展,满足大规模数据存储和高并发访问的需求。
2、分布式架构优势
许多非关系型数据库采用了分布式架构,数据被自动分布在多个节点上,并且具备数据冗余和容错机制,即使部分节点出现故障,也不会影响整个系统的数据可用性和服务连续性,保证了系统的高可靠性和稳定性。
(三)性能优势明显
1、读写分离
一些非关系型数据库支持读写分离操作,即将写操作和读操作分配到不同的服务器或节点上进行处理,这样可以充分利用硬件资源,提高系统的并发处理能力和响应速度,尤其适用于读多写少的场景,如新闻资讯网站等。
2、高效的索引和查询机制
针对不同的数据模型和查询需求,非关系型数据库设计了专门的索引结构和查询算法,文档数据库中的全文索引可以快速实现对文本内容的模糊搜索;图形数据库中的专用遍历算法能够高效地处理复杂的关系查询,大大提升了数据检索的效率。
四、非关系型数据库的应用场景
(一)互联网行业
1、社交网络
社交媒体平台如微博、微信等需要处理海量的用户关系数据和动态信息,非关系型数据库中的图形数据库可以很好地表示用户之间的关注、好友等社交关系网络,同时结合文档存储可以方便地存储用户的个人资料、发布的动态内容以及评论等信息,为社交网络的高效运行和个性化推荐等功能提供有力支持。
2、电子商务
电商平台面临大量的商品信息管理、用户订单处理以及客户评价等数据,使用文档数据库可以灵活地存储各种商品属性和描述信息,方便进行商品搜索和推荐;而列族存储则适用于处理订单数据,能够快速统计销售情况和用户购买行为等信息,帮助企业进行精准营销和库存管理。
(二)大数据领域
1、日志分析
在互联网企业中,每天都会产生大量的服务器日志、用户行为日志等数据,这些日志数据具有数据量大、格式多样且增长迅速的特点,非关系型数据库可以快速接收和存储日志数据,利用其强大的水平扩展能力和高效的数据处理方法,对日志进行分析和挖掘,如统计用户访问量、分析流量来源、检测异常行为等,为企业的运营决策提供有价值的依据。
2、数据仓库
随着企业数据的积累和业务的多样化,传统的数据仓库在处理海量数据和复杂查询时面临挑战,非关系型数据库可以作为数据仓库的补充或替代方案,通过其灵活的数据模型和高效的查询性能,更好地整合和分析来自不同数据源的数据,为企业的数据分析和商业智能应用提供更强大的支持。
(三)物联网行业
1、设备数据采集与管理
物联网环境中存在着大量的传感器设备和智能终端,它们会产生海量的实时数据,非关系型数据库可以高效地采集和存储这些设备上传的数据,如温度、湿度、位置等信息,其灵活的数据模型能够适应不同设备产生的数据格式差异,并且可以通过与云计算平台的结合,实现对物联网设备的远程监控和数据可视化展示。
2、实时数据处理与分析
在物联网应用中,往往需要对实时数据进行快速的处理和分析,以便及时做出决策或响应,非关系型数据库具备良好的实时数据处理能力,能够在短时间内对新采集的数据进行分析和计算,如预测设备故障、优化能源消耗等,为物联网系统的智能化运行提供保障。
五、非关系型数据库面临的挑战与发展趋势
(一)面临的挑战
1、事务处理能力相对较弱
虽然非关系型数据库在很多方面具有优势,但在事务处理的一致性和完整性方面,相比传统的关系型数据库还有一定差距,在一些对事务要求极高的金融、银行等核心业务领域,非关系型数据库的应用受到了一定限制。
2、工具和生态系统不成熟
与关系型数据库相比,非关系型数据库的发展历史较短,相关的开发工具、管理工具和技术支持体系还不够完善,开发人员在使用非关系型数据库时,可能会面临学习成本较高、调试困难等问题,这也在一定程度上影响了其更广泛的应用。
3、数据迁移难度较大
企业在考虑从传统关系型数据库向非关系型数据库迁移时,面临着数据结构转换、应用程序改造等诸多难题,由于两种数据库的数据模型和操作接口存在较大差异,数据迁移过程需要投入大量的时间和人力进行数据清洗、转换和测试工作,以确保数据的完整性和一致性以及应用程序的正常运行。
(二)发展趋势
1、加强事务处理能力
随着技术的不断进步,非关系型数据库厂商正在致力于提升其事务处理能力,开发出更加完善的事务模型和一致性保证机制,以满足更多对事务要求较高的应用场景需求,一些新型的分布式事务协议的出现,为非关系型数据库在复杂业务环境下的应用提供了可能。
2、完善工具和生态系统
为了降低开发人员的使用门槛和提高开发效率,非关系型数据库的工具链和生态系统正在不断完善,出现了更多专业的开发工具、数据迁移工具以及可视化管理界面,同时也有更多的开源社区和技术论坛为企业和开发者提供技术支持和交流平台。
3、与人工智能和机器学习的融合
非关系型数据库与人工智能、机器学习的结合将是未来的重要发展方向,通过将非关系型数据库中存储的海量数据作为机器学习的训练数据源,可以实现更精准的数据挖掘、预测分析和自动化决策,在医疗领域,可以利用非关系