在当今科技飞速发展的时代,人工智能领域的一颗璀璨明珠——强化学习,正逐渐改变着我们的生活与世界,它宛如一位智慧的领航员,引领着智能体在复杂的环境中不断探索、试错、学习,进而做出最优决策,为诸多领域带来了前所未有的变革与突破。
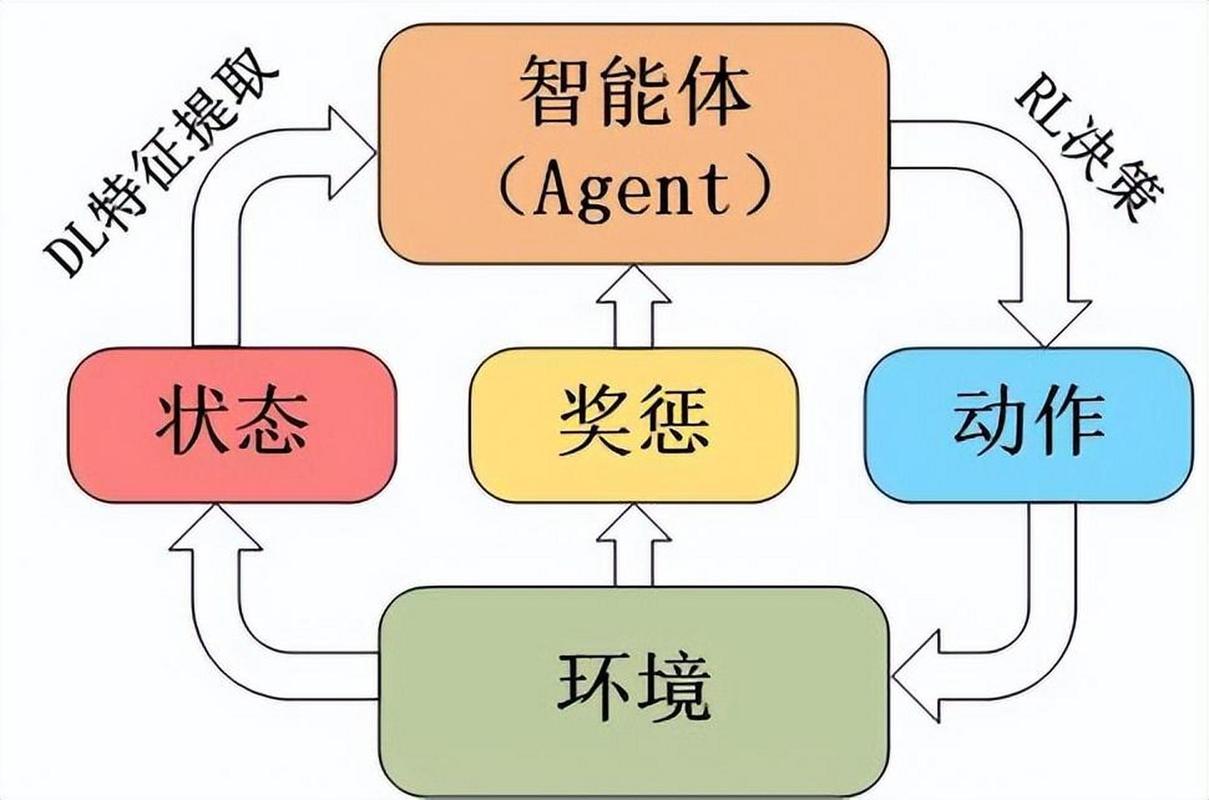
强化学习的核心思想源于行为主义心理学,其本质是一种基于奖励与惩罚机制的机器学习方法,智能体(agent)在一个特定环境(environment)中采取行动(action),根据环境反馈的奖励信号(reward)来调整自身的行为策略,以最大化长期累积奖励为目标不断进化,这一过程恰似人类在未知世界中摸索前行,通过经验积累与自我修正,逐步掌握应对各种情境的最佳方式,婴儿在学习走路时,每一次成功迈出一小步并保持平衡会获得内在的满足感与家长的鼓励,这便是正向奖励,促使其不断尝试、改进走路姿势与动作,逐渐熟练掌握行走技能;而摔倒则是负面反馈,提醒婴儿调整步伐与重心,避免再次失误,强化学习正是借鉴了这一自然学习规律,赋予机器类似人类“趋利避害”的学习本能。
深入探究强化学习的运行机制,不得不提及几个关键要素,首先是策略(policy),它定义了智能体在给定状态下应采取何种行动的概率分布,犹如一场棋局中的布局思路,策略决定了智能体每一步的行动倾向,是从稳健防守到主动进攻,或是灵活周旋,皆由策略指引,例如在围棋对弈中,不同的棋手有不同的行棋风格与策略,或注重实地抢占,或偏好外势构筑,这些策略影响着他们在棋盘上每一次落子的抉择,价值函数(value function)如同地图上的坐标系,用于评估智能体在特定状态下采取某策略所能获得的长期价值,它是对未来奖励的预测,帮助智能体判断当前所处状态是否优越,是通往成功决策的关键线索,想象一位探险家在神秘岛屿探寻宝藏,价值函数能依据已探索区域的信息、剩余路程的风险等因素,预估每一条路径最终找到宝藏的可能性及收益,从而辅助探险家规划最优路线,奖励信号作为环境的即时反馈,是强化学习的驱动力源泉,它可以是明确的数值奖励,如在游戏中通关得分、工业生产线上的产品合格加分;也可能是隐性的激励,像用户对智能推荐系统的认可度提升、机器人在复杂任务中效率的提高等,这些奖励信号引导智能体不断靠近目标。
随着技术浪潮的推进,强化学习已在众多领域绽放光彩,在游戏领域,它无疑是一位耀眼的明星,AlphaGo 击败人类围棋冠军李世石、柯洁的传奇故事广为人知,DeepMind 团队开发的 AlphaGo 借助深度神经网络与海量棋局数据训练,通过强化学习自我对弈数百万盘,不断优化策略与价值判断,其精湛的棋艺与超凡的决策能力令世界惊叹,这不仅标志着人工智能在复杂智力博弈中超越人类,更为强化学习算法的有效性提供了极具说服力的例证,激发了全球科研人员对其深入研究的热情。
在自动驾驶领域,强化学习同样发挥着不可替代的作用,汽车行驶的道路环境瞬息万变,从交通拥堵的城市街道到蜿蜒曲折的乡村小道,从晴空万里到暴雨倾盆,每一个决策都关乎生命安全与行车效率,自动驾驶系统利用强化学习让车辆智能体在模拟与真实路况中反复训练,学习如何在各种复杂场景下精准控制车速、转向、刹车等操作,以最小化事故风险、缩短行程时间并保障乘客舒适体验为目标,持续优化驾驶策略,在面对突发行人横穿马路的紧急情况时,经过强化学习的自动驾驶车辆能够迅速分析行人位置、速度、道路状况等多维度信息,权衡急刹车可能导致的追尾风险与适度减速避让的安全性,做出最合理的制动决策,确保行车安全。
工业制造领域亦是强化学习的用武之地,生产线上,机器人承担着重复繁琐且高精度的任务,如装配零部件、检测产品质量等,强化学习可助力机器人自主学习最佳作业路径与操作手法,提高生产效率与产品质量稳定性,以电子产品组装为例,机器人通过与环境交互试错,强化学习如何快速准确地抓取微小零件、精准对位安装,在不断积累经验过程中减少装配误差,提升产品良品率,降低生产成本,推动工业制造向智能化、高效化迈进。
尽管强化学习取得了显著成就,但仍面临诸多挑战,样本效率低下问题较为突出,智能体需大量样本才能学习到有效策略,在数据获取成本高昂或现实环境难以提供充足样本的场景中举步维艰,例如在医疗手术机器人研发中,因真实手术案例有限且涉及患者安全风险,难以获取海量数据供机器人学习不同病症下的精准操作策略,强化学习算法的可解释性欠佳,深度学习模型常被视为“黑箱”,难以理解其决策背后的逻辑依据,这在对可靠性与透明度要求极高的领域如金融风险决策、航空航天控制等应用受限,而且,真实世界环境的高维连续状态空间使得智能体状态表示与决策难度剧增,如机器人在复杂地形行走时需同时考虑数百上千个环境变量,对算法的计算资源与处理能力提出严峻考验。
科研人员并未停下探索的脚步,迁移学习试图将源任务中学到的知识迁移至目标任务,减少数据需求;解释性方法如可视化分析、规则提取等正努力揭开强化学习决策的神秘面纱;深度强化学习结合深度神经网络强大的表征能力与强化学习决策优势,不断提升算法在高维环境中的性能表现。
展望未来,强化学习有望在更多领域掀起创新风暴,在智能城市管理中,优化交通流量调度、能源分配等复杂系统;于教育领域,为个性化学习路径规划提供精准策略;在生物医学研究中助力药物研发、疾病诊断模型构建等,随着技术的持续革新与突破,强化学习将不断拓展人类赋予机器智能的边界,引领我们迈向更加智慧、便捷、高效的未来世界,成为人工智能发展历程中一座永不褪色的里程碑,深刻塑造着人类社会的生产生活方式与文明进程。