在人工智能的广袤天地里,强化学习宛如一颗璀璨星辰,散发着独特而迷人的光芒,引领着智能体在复杂环境中不断试错、学习与成长,为实现高度智能化的目标铺就道路,它的独特之处在于摒弃了传统监督学习对海量精准标注数据的依赖,转而让智能体像孩童探索未知世界般,凭借与环境交互所获得的奖惩反馈,自主摸索出最优行为策略。
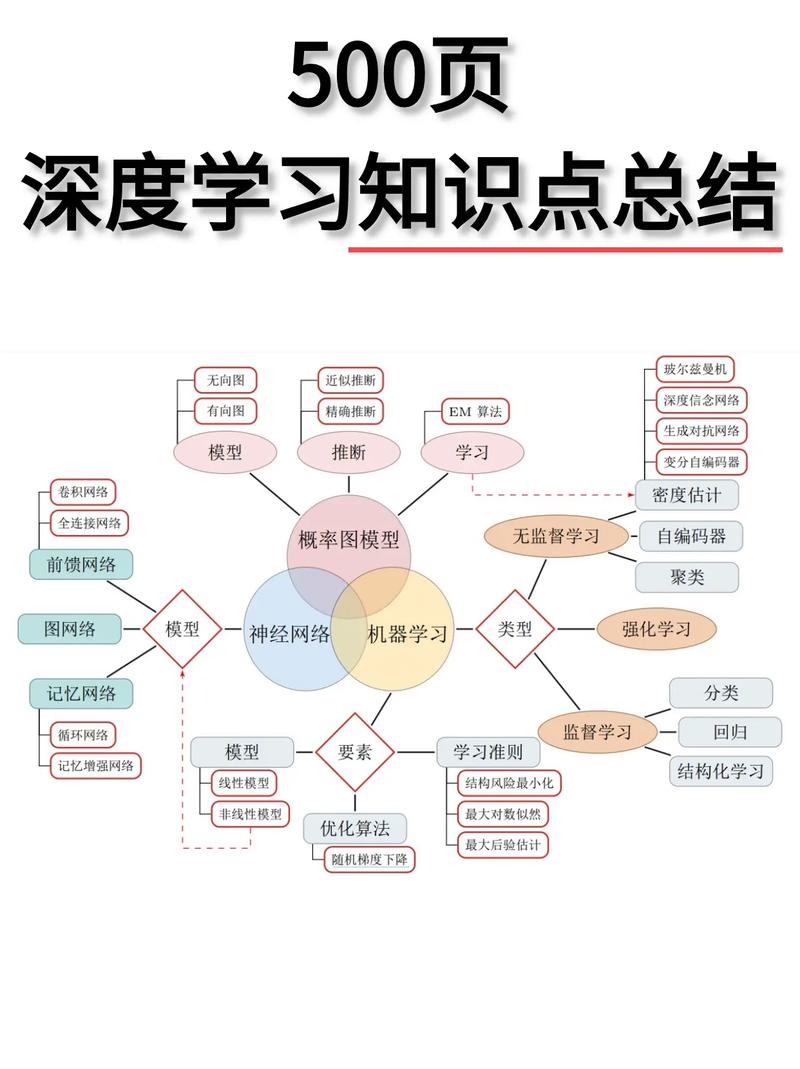
从理论基础而言,强化学习的核心框架基于马尔可夫决策过程(MDP),MDP 犹如一座精密数学大厦的基石,由状态空间、动作空间、状态转移概率及奖励函数构成,想象智能体置身游戏棋盘(状态空间),手持有限棋子走法(动作空间),每一步落子依据既定规则(状态转移概率)前行,而棋局胜负或得分评判(奖励函数)则指引其趋向胜利,智能体任务是依据过往经验,预估未来奖赏,借由策略函数抉择当下动作,以累积长期回报最大化,此长期回报计算常运用折扣因子,权衡即时奖赏与未来预期,凸显策略规划前瞻性,如玩围棋,智能体既要考量当前吃子获利,更要布局长远,谋全局胜势。
深入探究强化学习算法脉络,Q-learning 作为离线学习方法典型代表脱颖而出,其核心在于构建 Q 表,存储“状态 - 动作”对及其对应 Q 值(即预期累计奖励),智能体依 Q 值大小挑选动作,每次交互更新 Q 值,遵循公式:新 Q 值 = 原 Q 值 + 学习率 ×(目标 Q 值 - 原 Q 值),目标 Q 值则取决于即时奖励、折扣因子与下个状态最大 Q 值,恰似探险家绘制宝藏地图,逐步精准标记各处“状态 - 动作”组合的价值,直至寻得最优路径,但 Q-learning 有局限,面对大状态空间易陷维数灾难,因需巨量存储维护 Q 表;且初期探索时 Q 值波动大、更新盲目,致学习效率低下,如新手盲目摸索迷宫出口,耗时费力且易迷失。
与之抗衡,策略梯度方法另辟蹊径,它直接参数化策略函数,借由优化策略参数提升动作选择质量,以 REINFORCE 算法为例,依策略梯度定理算出梯度,沿梯度上升方向更新策略参数:新策略参数 = 当前策略参数 + 学习率 ×(优势函数 × 奖励梯度),优势函数衡量各动作相较于平均表现优劣,奖励梯度反映奖励对策略参数敏感度,恰似雕琢璞玉,依纹理色泽(奖励信息)精准打磨策略形状(参数),塑造高性能决策模型,不过,策略梯度算法受高方差困扰,因奖励稀疏、波动大,每次更新步长不定,易使策略发散失稳,如同海浪中颠簸小船,难以平稳靠岸。
为攻克难题,深度学习强势嵌入强化学习,催生深度强化学习(DRL),DRL 以深度神经网络为智能体“大脑”,高效处理高维感知输入,如在图像识别游戏中,卷积神经网络自动提取图像关键特征,替代手工设计低维状态表示,极大拓展智能体认知边界,AlphaGo 便是 DRL 杰作,融合深度卷积网络评估棋局形势、策略网络选点与蒙特卡洛树搜索规划落子,以超凡实力战胜人类顶尖棋手,彰显 DRL 强大潜力,但 DRL 训练稳定性欠佳,网络复杂致过拟合风险攀升;样本相关性高、探索效率低,易陷入局部最优,急需创新技术破局。
于实际应用层面,强化学习成果斐然,机器人领域,FetchRobotics 仓储机器人借强化学习自主导航搬运货物,穿梭货架间精准避障、优化路径,大幅提升物流效率;医疗影像诊断中,智能算法经海量病例“训练”,辅助医生快速精准标识病灶、拟定治疗方案,成临床诊疗得力助手;游戏开发更是强化学习“试验田”,从简单雅达利游戏到复杂 MOBA 竞技,智能体不断刷新战绩,催生游戏 AI 革新,倒逼玩家提升技艺,丰富电竞生态内涵。
展望未来,强化学习前景壮阔却也挑战重重,理论上,需完善多智能体协同、迁移学习等机制,攻克信用分配难题,让智能体在动态复杂群体环境高效协作、举一反三;实践中,要聚焦算法稳健性、可解释性提升,确保关键场景可靠运行、决策透明可信;伦理道德层面,规范 AI 行为准则,防止恶意利用、歧视偏见滋生,使强化学习在科技进步浪潮中稳健续航,赋能人类社会可持续发展,为智能时代写下浓墨重彩篇章。