在当今数字化时代,数据如同汹涌澎湃的洪流,以前所未有的速度和规模席卷而来,面对海量、复杂且多样化的数据,传统的数据处理方法早已捉襟见肘,大数据开发工具应运而生,成为企业在数据海洋中航行的关键舵手,助力其挖掘数据价值,驱动业务创新与决策优化。
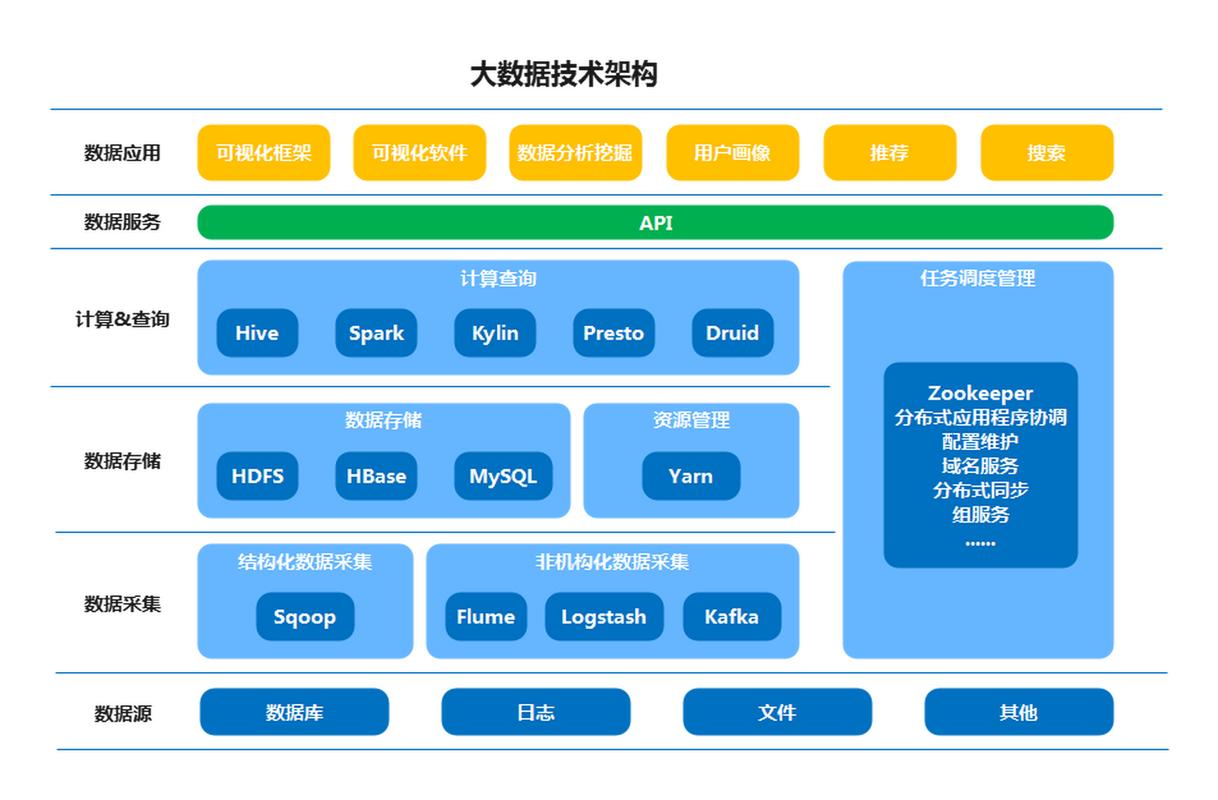
Hadoop 作为大数据领域的基石性工具,宛如一座坚实的数据存储与处理堡垒,它由 HDFS(分布式文件系统)、MapReduce(分布式计算框架)等核心组件构成,HDFS 以其高容错性和强大的扩展能力,能够轻松应对PB级乃至EB级的海量数据存储需求,将数据分散存储在集群中的不同节点上,确保数据的安全可靠与高效访问,MapReduce 则巧妙地将复杂的数据分析任务分解为 Map 和 Reduce 两个阶段,通过并行计算极大地提升了数据处理效率,为大规模数据集的批处理提供了有力支持,无论是日志分析、数据挖掘还是机器学习算法的训练数据预处理,Hadoop 都展现出卓越的性能与稳定性。
Spark 犹如一颗璀璨的新星,在大数据开发天空中闪耀着独特光芒,它以内存计算为核心优势,摒弃了传统磁盘 I/O 密集型计算方式,使得数据处理速度较 Hadoop 提升了数倍甚至数十倍,Spark 提供了丰富的 API,包括 Spark SQL、Spark Streaming、MLlib(机器学习库)和 GraphX(图计算库)等,涵盖了从批处理到实时流处理、机器学习以及图计算等多个领域,开发者可以在同一生态系统中流畅地切换使用不同的功能模块,实现一站式大数据处理与分析解决方案,在电商平台的实时用户行为分析场景中,Spark Streaming 能够迅速捕捉用户的浏览、点击、购买等操作信息,并即时进行统计分析,为精准营销、库存管理等提供实时决策依据;而 MLlib 则可基于海量用户数据构建个性化推荐模型,提升用户购物体验与平台销售额。
Flink 则专注于实时流处理领域,以其低延迟、高吞吐量和精准的状态管理机制脱颖而出,在金融风险监测、物联网设备数据实时分析等对时效性要求极高的应用场景中,Flink 能够精确地处理每一条流入的数据流,确保在事件发生的瞬间即可做出响应,其独特的状态后端设计,如 RocksDB 等嵌入式键值存储,使得 Flink 在处理有状态的复杂流式计算任务时更加高效可靠,避免了因状态丢失或不准确而导致的计算误差,为实时数据分析与业务流程的无缝融合奠定了坚实基础。
Kafka 作为一款高性能的消息队列系统,在大数据传输与分发环节扮演着至关重要的角色,它以其高吞吐量、可持久化、支持多订阅者等特性,成为大数据架构中数据流动的“高速公路”,在日志收集系统中,各个服务节点产生的日志信息可以源源不断地发送到 Kafka 主题中,消费者程序则可以根据不同的业务需求订阅相应的主题,进行日志解析、异常检测等后续处理,实现了数据生产者与消费者之间的高效解耦与异步通信,提升了整个系统的可扩展性与可靠性。
大数据开发工具并非孤立存在,而是相互协作、相辅相成,共同构建起强大的数据处理生态体系,企业与开发者需深入理解各工具的特性与优势,根据具体的业务场景与数据处理需求灵活搭配使用,方能在大数据的浪潮中乘风破浪,充分释放数据资产的潜在价值,为企业的发展注入源源不断的动力,开启智慧商业的新篇章。